To use DeFi services, the average consumer does not usually interact directly with the smart contracts on the blockchain, but we usually interact as usual with a traditional web-based or Android/iOS-based user interface, which in turn accesses smart contracts, which run on blockchains. Because of the decentralized nature of the underlying blockchain, this new type of application is referred to as “distributed applications” – or dApps for short. The term “Web 3.0 applications” is often used in this context. In this article we want to look at the basic Web 3.0 application architecture. What is this supposed to get you? Quite simply: A lot! Because without a minimal understanding of the most important components of Web 3.0, you are just clicking through the DeFi services without having an understanding of what is happening behind the scenes and what risks you are exposing yourself to in which step. So let’s dive into the realm of architects!
First of all we need an understanding of the differences between Web 1.0, Web 2.0 and Web 3.0. Here is a short essay on this:
- Web 1.0 – Web 1.0 is the beginning of the web. Many of us didn’t even experience this “primordial web” ourselves… and the older semesters among us (to which I count myself) have partially successfully suppressed it. In a nutshell: In Web 1.0, static web pages were common, which were written by central organizations. The user merely consumed the information.
- Web 2.0 – Today’s Web 2.0 is characterized by dynamic websites whose content is tailored as much as possible to each individual user. The website content is often written by the users themselves (keyword “user generated content”). Typical Web 2.0 applications are social media applications or blogs. Web 2.0 is dominated by the gigantic servers and centralized databases of the world’s Googles and Facebooks.
- Web 3.0 – In the Web 3.0 world, we are throwing away the centralized servers and databases and replacing them with blockchains and other decentralized solutions. More on that later in this article.
Architecture of a Web 2.0 application
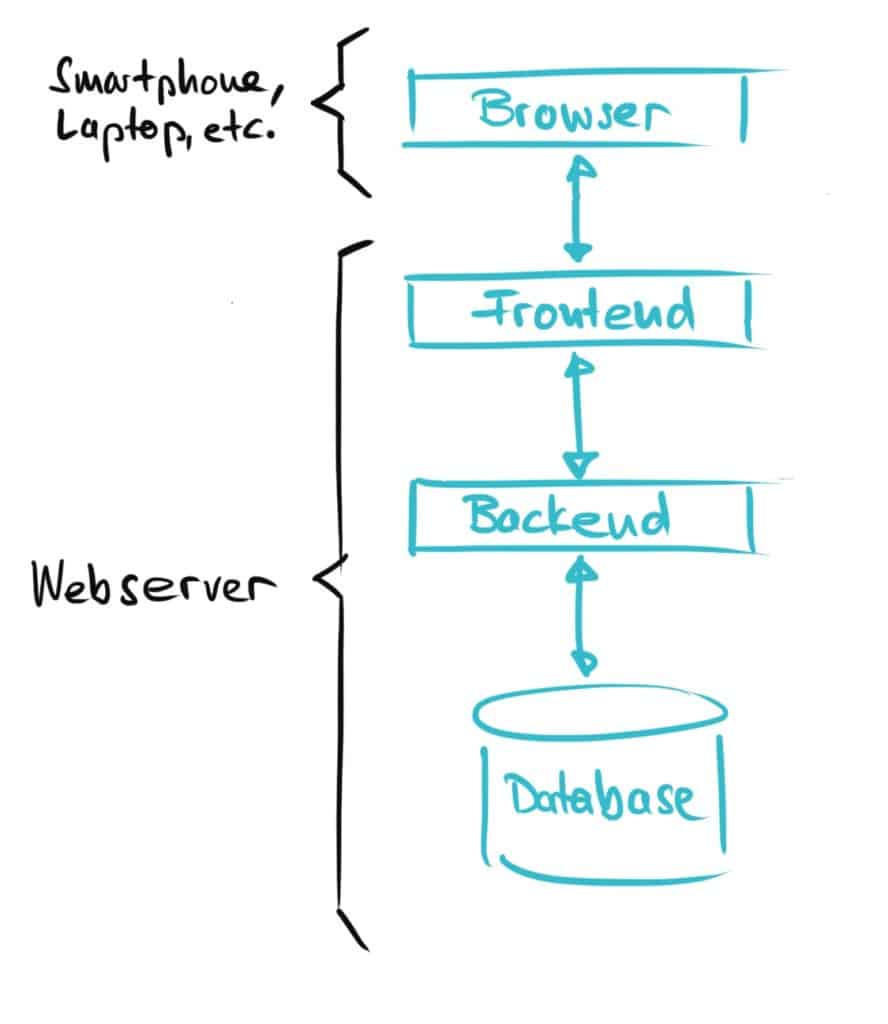
Next, let’s take a look at the typical architecture of a Web 2.0 application:
- First of all we need a frontend with which the user can interact. The front end for web applications is based on HTML and Java Script.
- Then you need the business logic that defines what happens when, for example, someone clicks the “Order now” button. The business logic is implemented in the backend using a programming language such as Java.
- And finally, we also need a data pot in which all user-generated data such as profile or order data can be stored. A database on the web server is used for this in Web 2.0.
Here is a summary of the architecture of a Web 2.0 application:
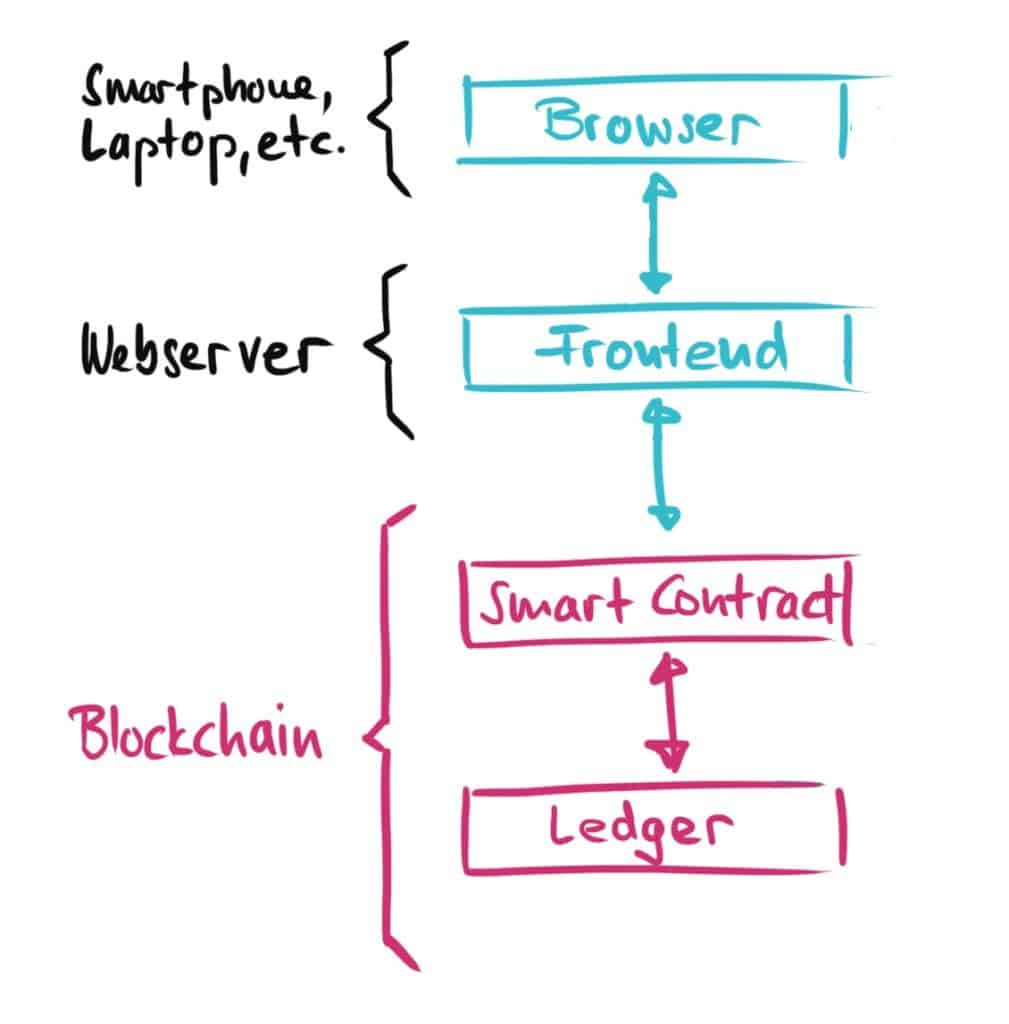
Architecture of a Web 3.0 application
In the Web 3.0 architecture we approach the whole thing completely differently: There is no centralized database and no business logic running on a server:
- In Web 3.0, we do not store transaction data etc. in a database, but in a decentralized blockchain such as Ethereum, which is operated jointly by all nodes of a distributed network.
- The situation is similar with the business logic: This is no longer operated on a central server at an Internet giant, but is formulated in the context of smart contracts (e.g. with the Solidity programming language for Ethereum smart contracts), which are then released an run on the blockchain. Thus, the business logic is publicly visible to everyone in this world and cannot be stopped from running by anyone in this world.
- But what about the frontend? Are we putting this on the blockchain too? No… actually it stays pretty much the same as in Web 2.0. We either have a web frontend running on a web server or an iOS/Android solution on our smartphone. But can’t we somehow decentralize the frontend as well? More on that later in this post.
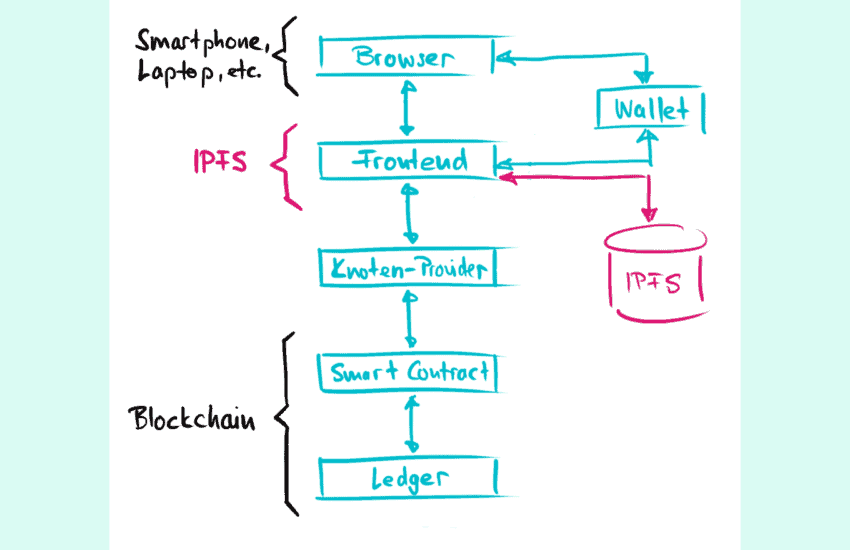
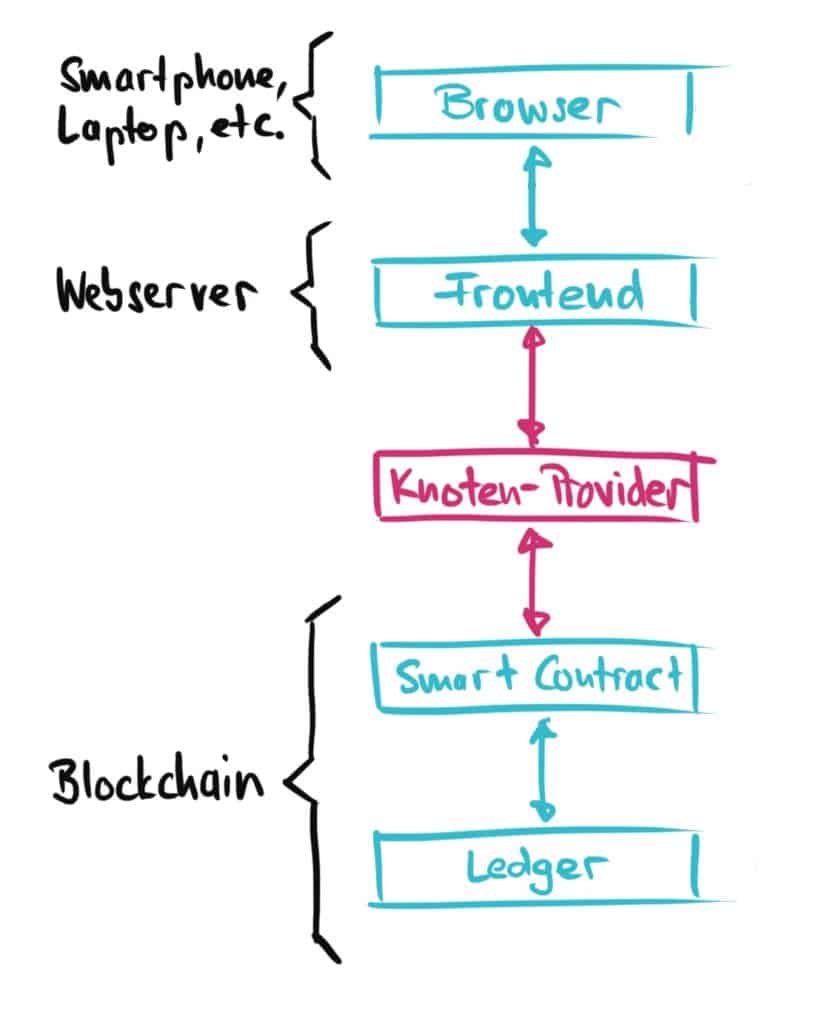
But… how do we connect the frontend to the smart contracts?
In Web 3.0 we can no longer simply connect the front end to a central web server, because the central web server has been replaced by a distributed network of computers (often also called network nodes), which operate the blockchain together and in a decentralized manner. But how do you connect to such a distributed network? Very simple: The frontend connects to a single node in the network, which, like every other node in the network, has a full copy of the blockchain stored locally and can therefore read and can push transactions into the network. The easiest way to do this is to use the services of a Network Node Provider. This saves you the ever more demanding work (and hardware requirements) of operating an Ethereum node yourself.
But… somehow there is still a wallet involved?!
The architecture outlined above works when it comes to reading information from the blockchain. We remember: The blockchain is a completely open, distributed list of data that can be viewed by everyone. Therefore, it is not a problem if our frontend wants to read and display data from the blockchain via network nodes. However, this is not quite so easy if a user wants to write data (or more precisely: transactions) to the blockchain via the frontend. As we all know, we can only write a transaction to the blockchain if we have first signed the transaction with our private key. That means we have to add a wallet like MetaMask to our architecture (comment: MetaMask is available as an extension for the web browser Chrome). Such a wallet stores the user’s private key and generates an alert for the user every time he is asked to sign a blockchain transaction with his private key.
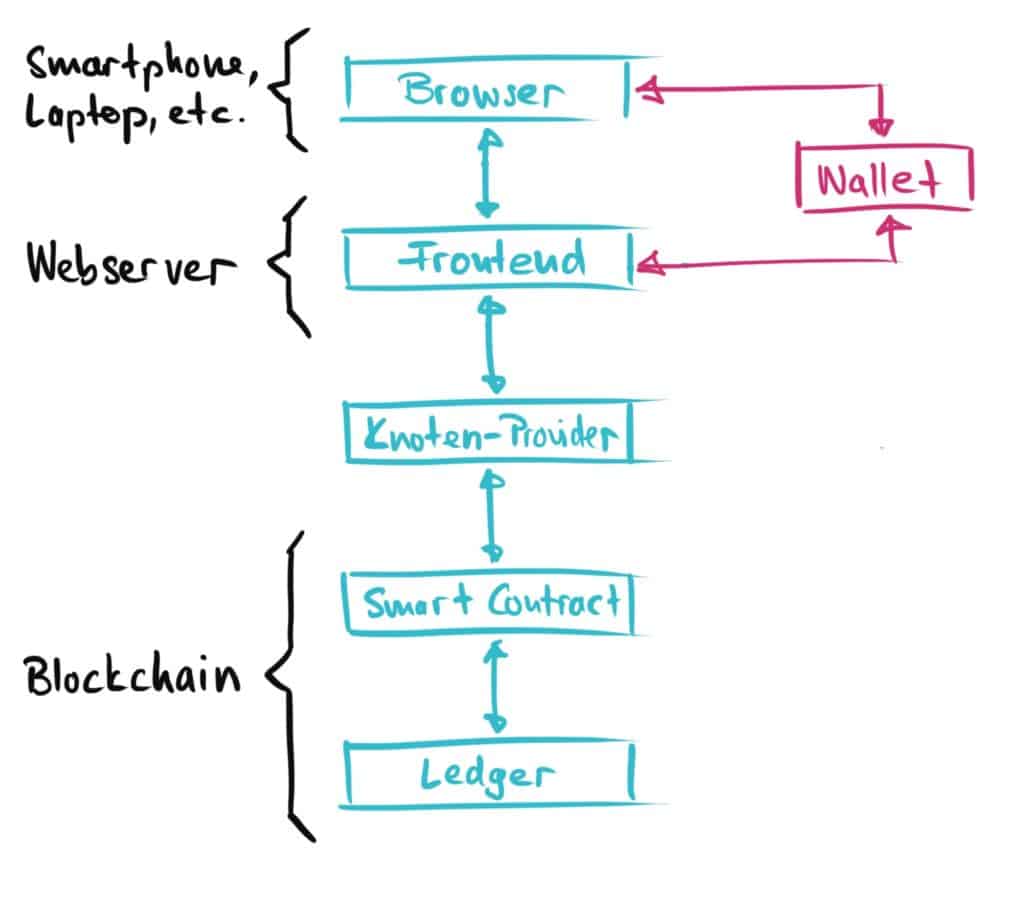
But… now we still have the frontend on Google Cloud or so!
The architecture picture above still has a few blemishes: If you have the frontend code running on a centralized web server such as Google Cloud, then a central organization can approach Google at any time and demand that our frontend be stopped… et voilà… we’re already out of business. Or another blemish: If we want to put all of our application’s data on blockchains like Ethereum, it will quickly become very expensive (e.g., for large multimedia files)!
How can we solve these problems around data storage? One approach uses storage methods that are decentralized (that’s the core: we want to replace centralized approaches with decentralized ones!), but do not run on the blockchain, but on a peer-to-peer network as we have seen in the pre-Spotify times at Napster etc. An example of such a distributed file system for storing and reading data is IPFS. The abbreviation stands for the pretty cool name “InterPlanetary File System” and is of course open source as usual for the decentralized world. As long as our frontend is still available on at least one single node of such a peer-to-peer network, our dApp is still up-and-running! Our final architecture now looks like this:
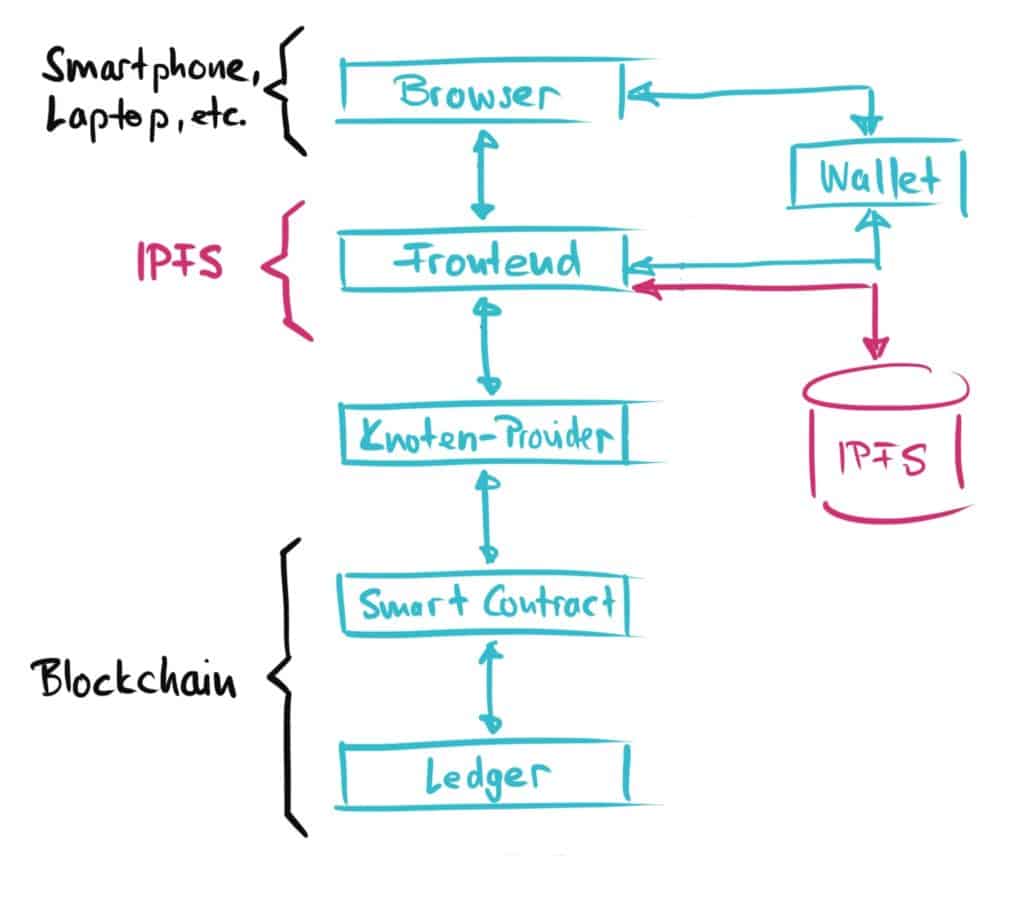
Now we have our Web 3.0 application architecture more or less complete. I hope this little exercise took your understanding of what DeFi (and other) dApps do and how they work to the next level!